データ構造とアルゴリズム(基礎理論)
学習のポイント
配列もデータ構造の一種といえます。データ構造とは「効率的にデータを管理する仕組み」です。色々な種類のデータ構造がありますので、しっかりとデータ管理の仕組みをマスターしましょう。
| 1. データ構造とは? | |||||||
| 「データ構造」とは、「データを表現するための枠組み」のことです。前節では、アルゴリズムを学習しましたが、ここではデータ構造について学習します。「プログラム」というのは、「アルゴリズム+データ構造」としてとらえることが出来ます。 | |||||||
| 2. データ構造の種類 | |||||||
| ●データ構造 ●基本データ構造 ●基本データ型 ●構造型 ●問題向きデータ構造 上記のような分類となります。 |
|||||||
| 3. 基本データ構造 | |||||||
| これは、「整数型」「実数型」「文字型」があります。その他として以下のものがあります。 ●論理型 論理演算に使用される変数の型で「True」と「False」の2値をとります。 ●列挙型 要素に順序をつけたものです。例えば、「CPU」「メモリ」「HDD」の場合 1番目:CPU 2番目:メモリ 3番目:HDD のように順序付けたものです。 一般的には、(CPU、メモリ、HDD)と表現します。 ●ポインタ型 「ポインタ」というのは、「データが格納されているメモリのアドレス」を格納します。通常、変数には、値が格納されていますが、それがメモリ上のどの番地(アドレス)かをポインタが格納することが出来ます。例えば変数「a」が100という値が格納されていて、アドレスが10番地の時、ポインタ型の変数には、「10」が格納されています。 ●構造型 「レコード型」とも言います。これは、「複数の基本データ型の1つにまとめたデータ型」です。例えば、以下の基本データ型があった場合、 ・生徒番号(文字列型) ・氏名(文字列型) ・得点(整数型) この3つをひとつのかたまりとしたものです。かたまりの名前が、「生徒成績」の時、上記の3つは、生徒成績の「メンバ」と言います。 指定方法は、生徒成績.生徒番号のように「.」ピリオドで区切ります。通常、構造体は配列と連携して管理するのが一般的です。これを「構造体配列」と言います |
|||||||
| 4. 問題向きデータ構造 | |||||||
| これには、以下の種類があります。 ●リスト ●スタック ●キュー ●木 ●2分検索木 ●ヒープ ●バランス木 |
|||||||
| 5. リスト | |||||||
「リスト」とは、「データ部」と「ポインタ部」の要素からなるデータ構造です。
●単リスト 1方向の順序を表し、最初にリストの先頭のアドレスが必要となります。 ●双リスト リストには、次要素と前要素の2個のポインタ部があり、双方向に順次を表現できます。最初に、先頭と末尾の要素のアドレスが必要となります。 ●循環リスト 末尾要素のポインタ部が先頭要素のアドレスを保持します。これにより要素は環状となります。 次に、要素の挿入と削除について説明します。 ●挿入 配列と違い、簡単に要素を挿入出来ます。これは、挿入する前のポインタ部の変更と挿入する要素のポインタ部の変更だけで済みます。 ●削除 削除する場合は、削除する前の要素のポインタ部を削除する要素の次の要素のポインタ部へ変更します。尚、削除された要素は、「ガーベジ」としてリストを再構成するまで残ります。これを完全に消すには、「ガーベジコレクション」を行う必要があります。 |
|||||||
| 6. スタック | |||||||
| 「スタック」とは、「後からに格納したデータを最初に取り出す」という「後入れ先出し(LIFO)」のデータ構造です。操作としては、PUSHとPOPがあります。 ●PUSH スタックにデータを格納する。 ●POP スタックからデータを取り出す。 また、スタックでPOPできる最上段の要素を管理しているポインタを「スタックポインタ」と言います。
スタックはサブルーチンの戻り値の番地を管理するのによく使用されます。 ●単リストによるスタックの実現 単リストで、スタックを実現するためには、 PUSHでリストの先頭にデータを追加して、POPでリストの先頭要素を取り出すという操作を行えば。リストの先頭が「最後に格納されたデータ」となり、これを最初に取り出すことにより「LIFO」を満たすことになります。 |
|||||||
| 7. キュー | |||||||
| 「キュー」とは別名「待ち行列」とも言います。キューは、「先に格納したデータが先に取り出すという先入れ先出し(FIFO)」のデータ構造です。 ●enQueue キューにデータを格納する。 ●deQueue キューからデータを取り出す。
●単リストによるキューの実現 単リストで「キュー」を実現するためには、enQueueで「リストの末尾にデータを追加」して、deQueueで「リストの先頭要素を取り出す」ことで実現できます。 |
|||||||
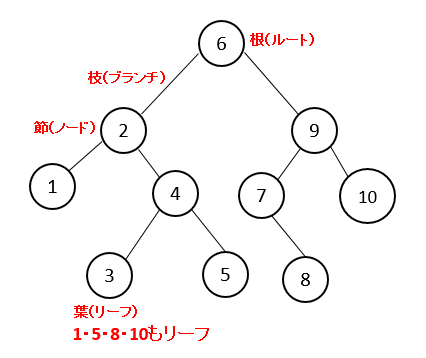
| 8. 木 | |||||||
| 「木構造」とは、データを階層的に表現したものです。 ・木構造は「節(ノード)」の集合である。 ・節の中の最上位を「根(ルート)」と呼ぶ。 ・節と節を結ぶ経路を「枝(ブランチ)または辺」と呼ぶ。 ・枝で結ばれた節で上位を「親」、下位を「子」と呼ぶ。 ・子を持たない節を「葉(リーフ)」と呼ぶ。
|
|||||||
| 9. 2分検索木 | |||||||
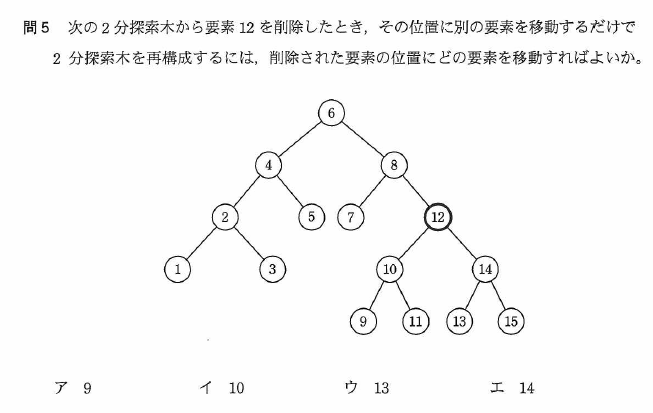
| 「2分検索木」とは、「2分木」の各点について以下の制約のもとに要素の値をつけたものです。 制約条件 ●ある節で、左の子のキー値がその節のキー値より小さい。 ●ある節で、右の子のキー値がその節のキー値より大きい。 よって「左部分木 < 親 < 右部分」の関係が成立します。 これにより検索を効率的に行うことが出来ます。 過去問題 平成25年春期 問5
問題文の2分探索木から要素12を削除すると、2分探索木の制約条件(上記参照)を保つためには、「要素11」または「要素13」である必要があります。正解は、ウです。 |
|||||||
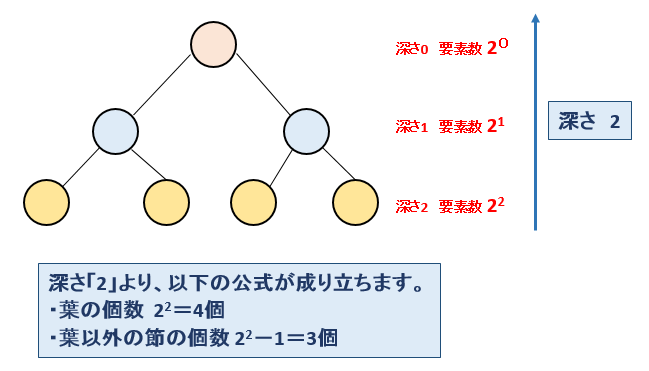
| 10. ヒープ | |||||||
| 「ヒープ」とは、以下の条件を満たす「完全2分木」です。 ●どの親子関係でも「親>=子または、親<=子」のような一定の大小関係が成立している。 これにより、根に最小値を格納した場合、親<=子の関係が成立した場合、データを順番に取り出すことによりデータを整列することができます。 |
|||||||
| 11. バランス木 | |||||||
|
バランス木とは、データを検索しやすいように、ある一定のバランスで葉のレベルを構成させた木構造です。以下の2種類があります。 ●AVL木とは、どのノードの「左右部分木の高さの差が1以下」という条件を満たす「2分探索木」のことです。 ●B木とは、すべての節で、左部分木と右部分木のレベルが同じ「多分木」のこどてす。 |
|||||||
| 12. 文字列検索のアルゴリズム | |||||||
| 「文字列検索」とは、対象の文字列の中に指定された文字列が存在するかどうか調べることを言います。具体的には、以下の2種類の方法があります。 ●力まかせ法(単純な検索) 例えば、「pafu」という文字列検索する時、最初に、配列の1番目から4番目を比較します。次に、配列の2番目から5番目を比較します。これを繰り返していきます。 ●BM法 対象の配列と1文字ずつ比較していくという点では、「力まかせ法」と同様ですが、検索する文字の右側から比較していきます。不一致の場合は、対象の配列の右端の文字によってスキップさせる数を変えて比較していきます。余計な比較をしないため、高速に行えます。 |