アルゴリズム(基礎理論)
学習のポイント
処理手順である「アルゴリズム」の基礎をマスターしましょう。フローチャート・疑似言語の表記について理解し、配列・検索・並び替え・オーダ記法・再帰アルゴリズムなどを理解しましょう。
| 1. アルゴリズムとは? | ||||||||||||||||||||||
| コンピュータでプログラムを記述する際に、どのような手順で行うか考え、整理することを一般的に「アルゴリズム」と言います。 通常、アルゴリズムには、以下のものがあります。 ●変数 データを格納するみのです。変数には基本的に自由な名前が付けられます。 ●値の代入 変数には、値を代入することができます。例えば、100→A。これは、Aという変数に100という値を代入しています。 ●変数の代入 変数には、他の変数の値を代入することができます。例えば、A→Z。これは、Aという変数の値をZという変数に代入しています。ここで注意点としては、Aの変数の内容は変化しません。 ●演算結果の代入 変数には、演算結果を代入できます。例えば、A+50→B。これは、Aの値に50を加算してBへ代入しています。 ●変数の型 変数には、取り扱うデータによって以下の種類があります。 ・整数型…整数を格納出来る変数。 ・実数型…実数を格納出来る変数。 ・論理型…trueかfalseの2値のみ扱う変数。 ・文字型…1文字を格納出来る変数。 ・文字列型…複数の文字を格納出来る変数。 ●流れ図 アルゴリズムでは、流れ図で表現する場合が多いようです。基本的に流れ図は、 「順次構造」…命令を順番に記述する。 「判断構造」…命令を条件によって分岐する。 「反復構造」…命令を条件を満たすまで繰り返す(ループ処理) より構成されます。しかし、流れ図は、上記の3種類の構造以外にも、どのようなアルゴリズムでも表現できてしまいます。つまり、GoTo文と言って、いくらでもアルゴリズムを複雑にできてしまいます。そこで、情報技術者試験では、「擬似言語」を導入しました。これは、GoTo文が一切、使用することが出来ず、かつ、上記の3種類の構造でアルゴリズムを表現することです。このような方法論を「構造化プログラミング」と言います。 |
||||||||||||||||||||||
| 2. 流れ図(フローチャート)入門 | ||||||||||||||||||||||
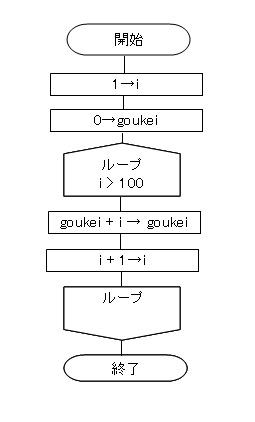
ここで実際に流れ図について考え見ましょう。以下の例は、1から100までの総和を求める流れ図です。
|
||||||||||||||||||||||
| 3. 擬似言語 | ||||||||||||||||||||||
上記の同様の処理を擬似言語で記述すると以下のようになります。
|
||||||||||||||||||||||
| 4. 配列 | ||||||||||||||||||||||
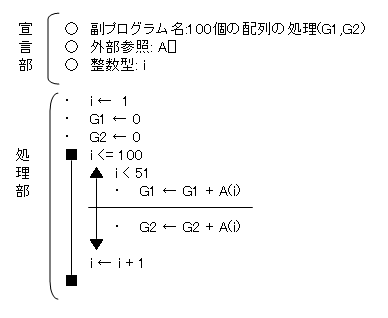
| 配列とは、変数の1種類で、「型が同じで変数名が同じである複数の要素をもつ変数の集まりです」。配列の要素を識別するためには「添字(インデックス)」を使用します。 例えば、Aとい名前の配列で100個の要素の場合、A(1)、A(2)・・・A(99)、A(100)というように表現します。配列は、ループ処理と使用することによりアルゴリズムを簡潔なものにします。 例えば、100個の配列のデータの内容を1から50までの要素は、G1に格納して51~100までの要素の内容はG2へ格納する処理を擬似言語で記述すると以下のようになります。尚、配列の添字は、「1から始まる」場合と「0から始まる」場合があります。
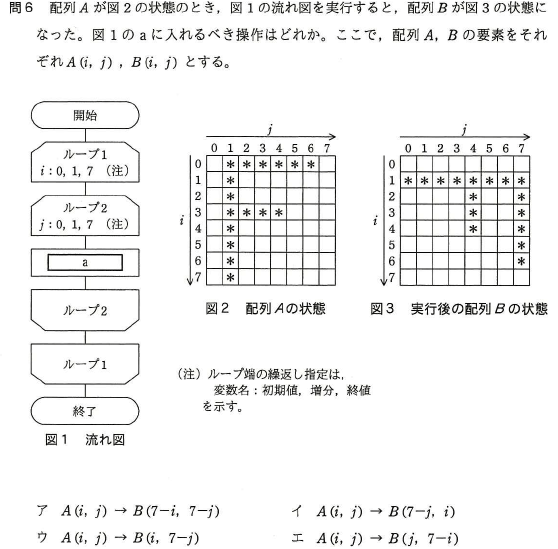
過去問題 平成27年秋期 問6
|
||||||||||||||||||||||
| 5. 最大値・最小値 | ||||||||||||||||||||||
以下は、配列の中から最大値を求めるアルゴリズムです。
|
||||||||||||||||||||||
| 6. 線形検索(リニア検索) | ||||||||||||||||||||||
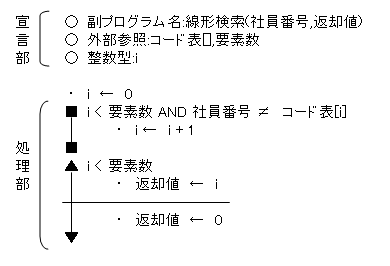
「線形検索」とは、「リニア検索」とも言います。これは、配列などに格納されているあるデータを探し出す処理のことを言います。例えば、配列に社員番号の「コード表」が格納されていて、これよりある人の社員番号を検索する場合を考えて見ましょう。
|
||||||||||||||||||||||
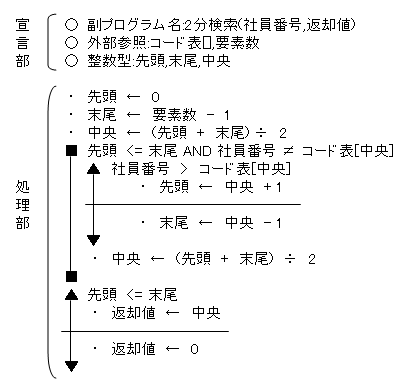
| 7. 2分検索 | ||||||||||||||||||||||
「2分検索」とは、前提条件として、検索対象の配列が昇順か降順に並んでいる時に、有効な方法です。これは、検索値と「配列の中央の要素」を比較します。これにより、検索値の方が大きければ、求める要素は右側に存在します。逆の場合は左側に存在します。この方法で検索を行っていきます。前節と同様に、配列に社員番号の「コード表」が格納されていて、これよりある人の社員番号を検索する場合を考えて見ましょう。
|
||||||||||||||||||||||
| 8. ハッシュ検索 | ||||||||||||||||||||||
|
ハッシュ検索とは、「ハッシュ関数」によって、「ハッシュ値」を算出して、ハッシュ値が示す場所にデータを格納します。この時のハッシュ値を「キー」といいます。これにより、「キー値」により検索データを求めます。検索時間は、データ件数が増えても「一定」となります。
但し、問題となるのが、「異なるキー値で同一のデータが検索される」という場合です。これを「衝突(シノニムの発生)」といいます。衝突がないように「オープンアドレス法」や「チェイン法」があります。 ●チェイン法(オープンハッシュ法) ハッシュ表には最初のデータのポインタだけを入れておき、衝突が発生した時に同じハッシュ値をもつ要素をリストを使用して格納する方法です。つまり、ある添字の箇所について横方向にリストを使用していきます。 ●オープンアドレス法(クローズドハッシュ法) 衝突が発生した場合、再ハッシュ(再度ハッシュ計算を行うこと)する方法です。
|
||||||||||||||||||||||
| 9. 整列(並び替え) | ||||||||||||||||||||||
| 整列とは。「ソート処理」のことを言います。データを昇順または降順に並べ替えます。 整列には単純なものとして、以下の方法があります。 ・選択法 ・交換法(バブルソート) ・挿入法 また、高速に整列の方法としては以下のものがあります。 ・クイックソート ・シェルソート ・マージソート ・ヒープソート |
||||||||||||||||||||||
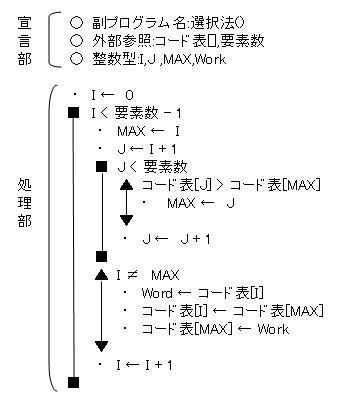
| 10. 基本選択法 | ||||||||||||||||||||||
「選択法」は、起点となる要素とそれに+1した隣の要素をループして比較してデータを交換していきます。これにより、起点となる要素を+1していき、最終的に並び替えが完了します。
|
||||||||||||||||||||||
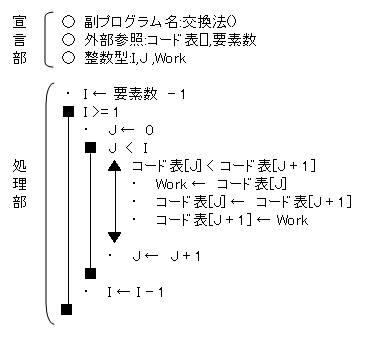
| 11. バブルソート(基本交換法) | ||||||||||||||||||||||
「バブルソート」とは、その名の通り、要素を交換しながら、並び替えを行います。つまり、起点となる要素を要素数-1から開始して、比較する要素を最初からループさせて大小比較により交換を行います。この処理を起点となる要素を-1していきます。
|
||||||||||||||||||||||
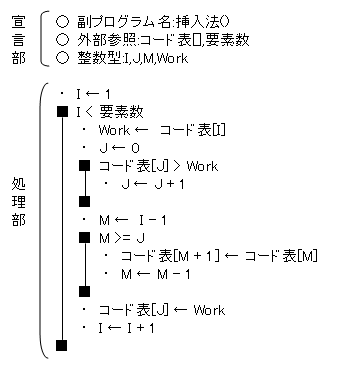
| 12. 基本挿入法 | ||||||||||||||||||||||
| 「挿入法」は、配列が整列済みと未整列部分から構成されている場合に有効な方法です。 基本的に、3つの添字を使用します。 ・「I」未整列部分の先頭の添字 ・「J」挿入位置を検索するための添字 ・「M」挿入位置を確保する添字
|
||||||||||||||||||||||
| 13. クイックソート | ||||||||||||||||||||||
| 「クイックソート」は、整列の対象の配列を分割しながら整列を進めます。具体的には、全データから基準値を選び、その値より「大きいデータ」と「小さいデータ」に振り分けます。この作業を繰り末して行います。また、クイックソートは、「再帰呼出し」と言って、「ある手続きの中から自分自身を呼び出す」方法を用いても実現できます。 整列の比較回数は(要素数がn個の時) 平均比較回数はn*Log2n回 最大交換回数はn2回 過去問題 平成21年秋期 問6
|
||||||||||||||||||||||
| 14. シェルソート | ||||||||||||||||||||||
| 「シェルソート」は、ある程度整列されたデータに対して有効である。この方法は、「挿入法」を応用して、一定間隔ごとにデータを振り分け、これを挿入法で整列させて、その間隔を順次、狭くしていく方法です。 | ||||||||||||||||||||||
| 15. マージソート | ||||||||||||||||||||||
| 「マージソート」は、既に整列された2個以上の配列を1つの配列に併合する処理を繰り返すことでソートを実現しています。つまり、「分割」して「整列」して「併合」を繰り返します。この方法は、補助記憶装置の大量のデータの並び替えなどに使用される「外部整列法」です。 | ||||||||||||||||||||||
| 16. ヒープソート | ||||||||||||||||||||||
| 「ヒープソート」は、「基本選択法」を応用した方法で、配列を「ヒープ」に変換します。ヒープとは、ルートに最大値が入り、親ノード>=子ノードの条件を満たした完全二分木のことを言います。昇順の場合は、ルートに最小値が入ります。 整列の比較回数は(要素数がn個の時) 平均比較回数はn*Log2n回 |
||||||||||||||||||||||
| 17. 計算量 | ||||||||||||||||||||||
| アルゴリスムの評価の方法のひとつに「処理するデータ件数」に着目して、「実行時間がどう増加し、上限値はどのくらいか」を示したものを「計算量」といいます。計算量を表す方法のひとつに「オーダ記法」があります。
例えば、N個の要素がある場合、N回の繰り返し回数の時、処理時間がデータ数Nに比例していることを「オーダ記法」を用いて、O(N)と表現します。 以下に今までのアルゴリズムをオーダ記法で表現します。
|
||||||||||||||||||||||
| 18. 再帰アルゴリズム | ||||||||||||||||||||||
| 「再帰」とは、ある手続の中で、その手続自体を使用することです。 例えば、以下の例を考えて見ましょう。 (問題) 関数F(S)で、S=5の時のこの関数の関数値はいくつか? 関数の仕様は F(0)=0、F(1)=1 F(S)=F(S-1)+F(S-2) 但しSは2以上とする (解説) ここで、S=5であるため、S=0~S=5までの計算を行います。 S=0の時、F(0)=0 S=1の時、F(1)=1 S=2の時、F(2)=F(2-1)+F(2-2)=F(1)+F(0)=1+0=1 S=3の時、F(3)=F(3-1)+F(3-2)=F(2)+F(1)=1+1=2 S=4の時、F(4)=F(4-1)+F(4-2)=F(3)+F(2)=2+1=3 S=5の時、F(5)=F(5-1)+F(5-2)=F(4)+F(3)=3+2=5 よって、5が解答となります。 |